

In a time of exponential data growth and increasing concerns over data security, the field of data governance is undergoing a profound transformation. With the implementation of strict regulations such as GDPR and CCPA, coupled with the complexity of managing vast volumes of data, organizations are realizing the importance of effective data management for gaining a competitive edge, ensuring regulatory compliance, and making well-informed decisions.
However, many companies continue to struggle with common challenges in implementing data governance. Issues such as a lack of data control, poor data quality, and multiple data silos with limited collaboration continue to persist.
In this article, we’ll explore the origins of these challenges and highlight how a data catalog can serve as a solution to overcome them and can lead to the streamlining of the entire data governance process.
What is Data Governance? A Quick Explanation
Data governance focuses on the effective management and control of an enterprise’s data assets. It includes various activities with the following objectives:
- Establishing robust policies and procedures
- Ensuring high standards of data quality and integrity
- Ensuring data availability and accessibility
- Complying with regulatory requirements
The primary goal of data governance is to foster accountability, transparency, and consistency of data across the organization in order to optimize its use for decision-making, analytics, and data science.
Typical activities of data governance include:
- Data access control: Regulating and managing permissions to ensure authorized usage of data
- Data lineage: Tracking and documenting the origin, transformations, and movements of data to provide a comprehensive understanding of its history and relationships
- Data classification: Categorizing and labeling data based on its sensitivity, importance, or other relevant attributes and implementing appropriate handling, storage, and protection measures in line with predefined policies
- Data discovery: Locating and identifying data assets within an organization’s systems or repositories to gain valuable insights and identify relevant sources
Why Data Governance Matters for Your Organization
In the fast-paced world of business, where organizations are constantly pushing forward, it’s easy to overlook a process as abstract as data governance. However, there are many reasons why data governance should be a priority for any forward-thinking organization.
Access
While the volume of data doubles every two years, a mere one percent of it gets harnessed. One reason for this is inadequate or overly complex access control policies. While these measures aim to mitigate the risk of unauthorized access, they can sometimes actually discourage data sharing and cause data silos. To strike the right balance between accessibility and security, organizations should adopt an approach similar to that of online banking security. Banks not only prioritize safeguarding their users’ information and assets but also ensure that their applications are user-friendly and easy to navigate.
Data Quality & Discovery
Beyond access controls, issues often arise around data quality and discovery, especially in distributed organizations such as data mesh architectures, where multiple teams generate models and assets for shared use. Alarming statistics from Salesforce reveal that approximately 91% of CRM data is incomplete, and around 70% of that data deteriorates and becomes inaccurate each year. Such inconsistencies, errors, or gaps in data create a lack of trust and underutilization, which can hamper strategic outcomes.
Let’s take a look at how Google operates. Google relies on surfacing websites created and maintained by others, but if these websites consistently present unreliable information, it tarnishes Google’s brand. Consequently, Google acts as a gatekeeper of information, prioritizing both discovery and quality for its users. Similarly, when managing data assets, it’s crucial that Google ensures discoverability while also providing insights into site quality. This requires recognizing the significance of data lineage, an often-niche IT concept that plays a vital role in maintaining data quality. It does so by inserting visibility into the business logic, which is often poorly documented in established data warehouses.
Data Privacy
The increasing collection and storage of personal or sensitive data exposes organizations to security breaches and legal concerns under regulations like GDPR and CCPA. According to Cisco 2023 Data Privacy Benchmark Study, 95% of organizations recognize the importance of ensuring that all employees have a clear understanding of data privacy protection. While it’s natural to be cautious when handling sensitive data, it shouldn’t prevent companies from harnessing its value. Take salary information, for example. By developing models to accurately calculate bonuses and provide valuable insights for cost projections to the Finance department, data analysts can deliver substantial value. However, effective management of sensitive data requires proper classification of data assets. This critical step ensures that specific information receives the necessary levels of care and protection.
The Approval Paradox: How It’s Putting Your Organization’s Data at Risk
A common response to security and governance challenges is to increase the number of approvals required for data access. While this approach is necessary, it’s impractical to have approvals for every critical data point within the organization.
Moreover, approval workflows quickly become obsolete, presenting a significant security challenge. Because approval workflows give managers and decision-makers a false sense of security, they might be unaware of real risks, such as data breaches.
Over time, approvals tend to accumulate under each employee. At the same time, many employees move around within organizations due to promotions and role transfers. In fact, LinkedIn Global Talent Trends Report 2022 highlights a rise in internal mobility in 16 out of 19 global industries. As employees transition to different roles, the mismatch between their assigned roles and their data access permissions increases.
In light of evolving data privacy laws and regulations, organizations must recognize that what they approved two years ago may no longer comply with current standards. Here’s the tricky part: once access is granted, many enterprises have limited visibility and often rely on manual processes to monitor recent accesses. This lack of ongoing oversight makes it challenging to perform regular checks and ensure continuous compliance.
Furthermore, data warehouses change faster than they used to. In the past, it would take more than a year to add a column to a data warehouse. However, with the spread of data lakehouses and data engineering practices adopting approaches similar to software engineering (such as CI/CD), data marts can be updated multiple times per day. Approving access for every change to the data marts is becoming impossible.
Data is no longer physically confined to a single location; it’s all around. Trying to consolidate all data in one warehouse is a losing game, given the sheer volume of data being generated daily by countless sources. Data could be located in SQL databases, data lakes, Sharepoint sites (I know…), Excel files on servers, and many other places.
Data Governance and Data Observability: Better Together
Manual approaches to data governance, as seen in the previous examples, quickly become complex, leading to inefficiencies, delays, and increased risks. Moreover, manual data governance lacks real-time visibility and transparency, hindering organizations from making proactive decisions. To enable timely and actionable insights, we recommend moving toward observability.
Observability, a fresh concept in Computer Science, allows organizations to understand the health and state of data in their systems based on external outputs such as logs, metrics, and traces. Unlike traditional monitoring that relies on predefined metrics and logs, observability provides a broader and more dynamic view of the system. It allows organizations to explore how and why issues occur rather than simply receiving alerts.
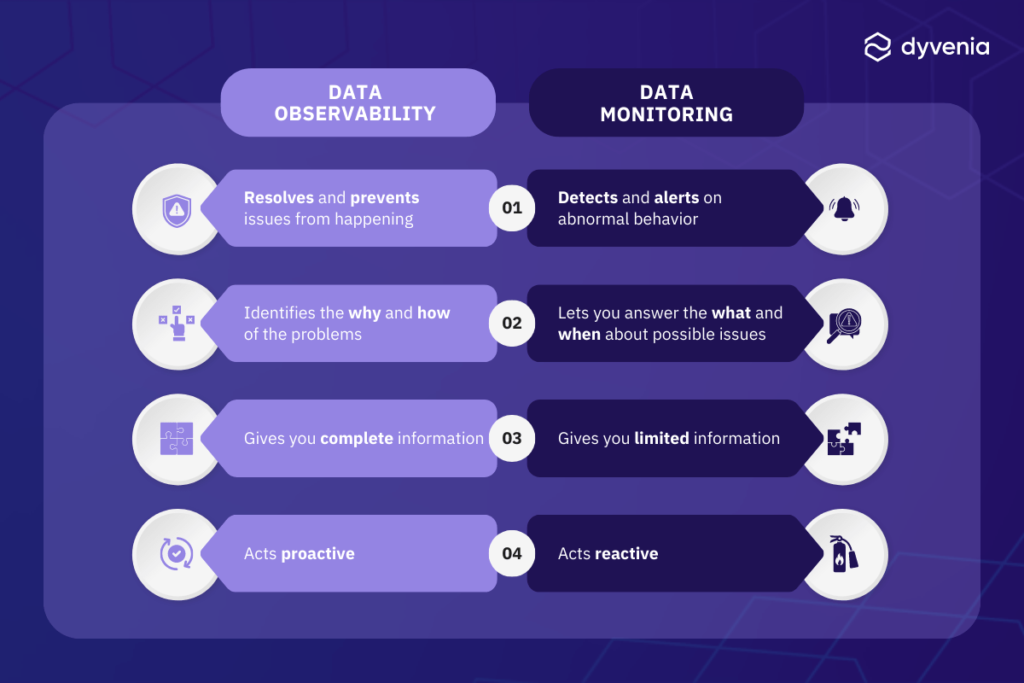
Through observability, organizations can monitor various aspects of data governance processes and systems. The key question becomes: “What can we observe about X?” or better yet, “What data can we collect regarding X?” By identifying the data we can collect about data governance and later, its usage, we ensure that we obtain data from each observable process.
Now, let’s delve into the practical application of observability and its impact on the primary drivers of a data governance initiative: access control, quality and freshness, as well as discovery and user experience.
Access ControlWhat data can we collect regarding access control?How can we utilize this data?
Quality and FreshnessWhat data can we collect regarding quality and freshness?How can we utilize this data?
Discovery and User ExperienceWhat data can we collect regarding discovery and user experience?How can we utilize this data?
Observability empowers organizations to ask more insightful questions about their data, enabling them to collect more relevant information that drives decision-making. So what should you focus on when applying observability to data governance?
We need to collect as much information as possible around our datalake/s, warehouses and reporting automatically so that we can use the information to control and monitor, but at the same time improve the users’ experience.
Though the process may seem complex at first, it becomes simpler with the right kind of data catalog at hand.
Data Catalog: Your Gateway to Observability and Empowered Governance
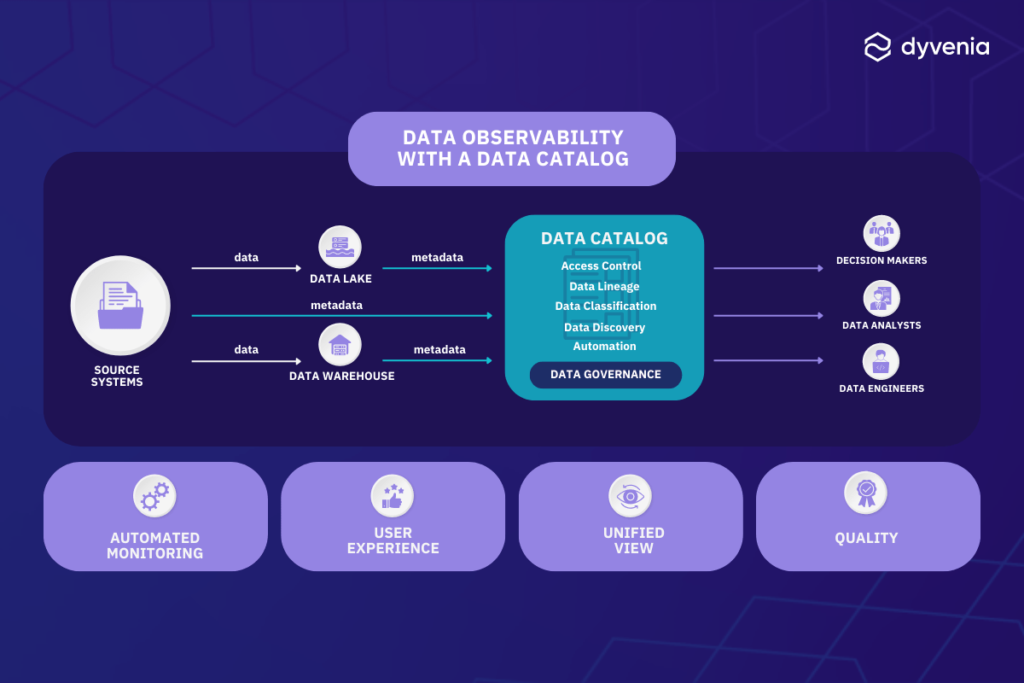
Automation is at the core of effective data governance. Once policies, regulations, and quality checks are established, constant monitoring becomes essential. As rules evolve, the monitoring system should adapt automatically, which will ensure compliance. This is where Data Catalogs prove invaluable as specialized tools designed to automatically collect metadata from data pipelines, lakes, and warehouses.
But automation can be a hard sell without a solid user interface. A good way to get interest (and funding) from businesses is to improve the overall experience of analytics and data science within the company. This is where a reliable data catalog truly shines. It has the power to present this collected information in a user-friendly manner, significantly enhancing the experience for data analysts, scientists, as well as dashboard and report users.
While it is technically possible to carry out governance without a catalog, doing so can lead to significant delays, particularly when relying on managed service providers for access management. Moreover, it carries the risk of making access decisions based on obsolete information. With a unified view of data, monitoring, and documentation, a data catalog streamlines the data governance process.
Getting Started
luma is our cutting-edge data catalog solution that empowers your organization to seamlessly locate, validate, and harness the power of your data.
Get started with luma today and unlock the full potential of your organization’s data. Contact our team of experts for a personalized demo and experience the future of data management.


